经典CNN网络结构总结(Classification)
概述
深度卷积网络架构(Deep Convolution Neural Networks, CNN)对图像的数据结构具有天然的适应能力,架构中包含了大量的参数,具有强大的数据容纳能力,能够自适应学习数据特征,从而提取到高层次语义信息,对复杂模型具有优异的拟合能力。与普通机器学习算法相比,CNN通过感受野能够学习到全局语义信息,架构的参数足够灵活,能够适应不同的视觉任务。
于此同时,CNN也存在很多不尽人意的地方。一方面,CNN存在大量的网络结构超参数,目前无法通过一个通用理论化的方法来确定,仍然需要人工做大量的实验来确定。不同的网络的收敛速度、最终的精度结构也大相径庭。另外一方面,CNN的结果是如何得到的,其结果的合理性解释也没法追溯,仍然是一个黑箱。
本文旨在总结现有比较成功的CNN网络架构,希望能够从中得到一些启发,其中总结了论文的思想、他人的设计经验,也穿插了很多个人的猜想,可能存在较多的谬误,希望将来能够不断的完善更正。
AlexNet
AlexNet是第一个尝试解决大规模复杂计算机识别任务,并取得巨大成功的CNN网络。AlexNet的网络结构为后续大量的CNN网络设计提供了参考,是最经典的网络结构之一。一方面,AlexNet引入了很多后续被广泛采用的网络模块:Rectified Linear Units ( ReLU )、Local Response Normalization ( LRN )和Overlapping Pooling。另外一方面,AlexNet提供了有效的防止过拟合的措施:Data Augmentation、Dropout和网络训练方法。
我对AlexNet主要贡献的理解:找到了一个用于解决复杂视觉识别任务的切实可行的CNN网络架构,有效解决了先前在神经网络/CNN容易过拟合的问题,使人们意识到了CNN巨大的潜力。以下主要对AlexNet的各个模块进行合理性解释(并不严谨)。AlexNet的网络结构如下:
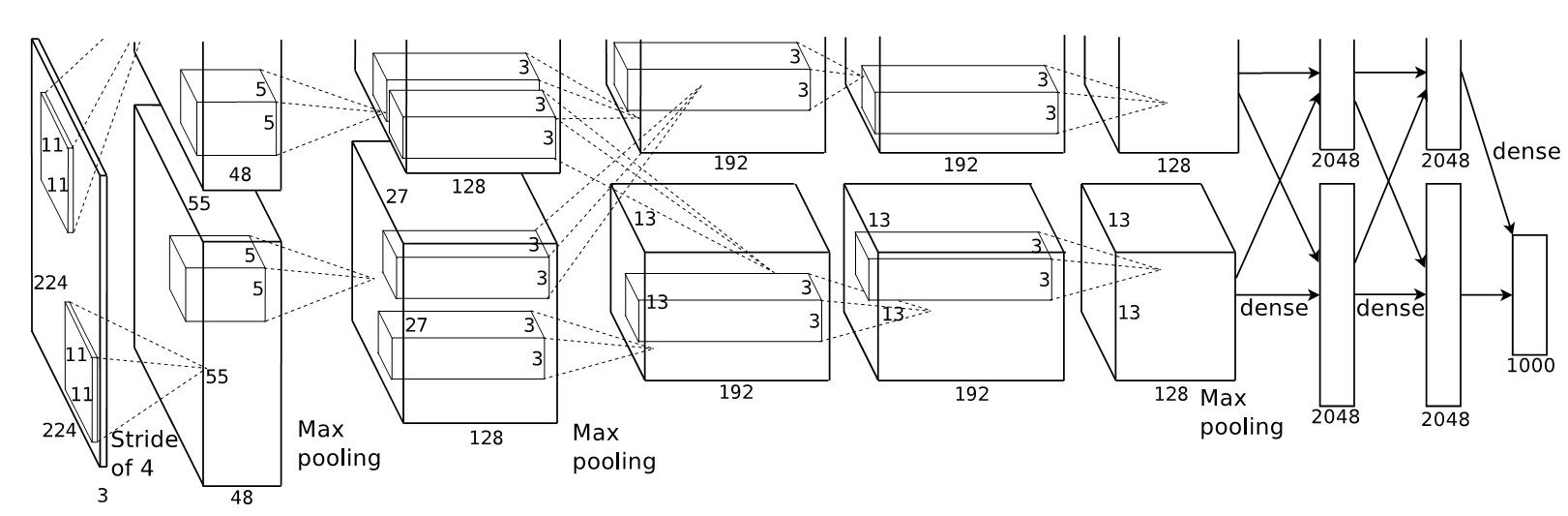
文章并没有过多的解释整体网络架构的设计思想。网络一个很大的特点是一开始将神经元分成了上下2组,在进行全连接的时候又合并成了一组,在第2卷积层输出的feature map在计算第3层的feature map的时候进行了交互。文章的解释是由于AlexNet的网络参数规模较大,无妨放置到一块GTX 580 CPU中,因此将网络分成了2部分。而第2层和第2层之间GPU数据的交互则是通过实验得到,可以有效提高网络的表现。
另外一个特点是就是网络第一层的卷积核大小为11×11,第二层为5×5,剩余的3层均为3×3。我认为这种方式是在网络浅层,输入图像分辨率较高,为了减少后续卷积层中feature map的大小和网络参数规模,先采用较大的卷积核对图像进行卷积,使得图像的大小能够快速减小,获得对底层特征(语义相对稀疏的地方)较大的感受野。
AlexNet中的具体网络模块的解释如下:
- ReLU:相对于之前的sigmoid激活函数和tanh激活函数,其计算量较小,不用计算超越函数,因此速度是上述激活函数的几倍。同时解决了以上激活函数,在训练过程中,容易出现的饱和现象,也就是梯度接近于零,网络训练慢的问题。总体来说,ReLU加速了网络的训练过程;
- LRN:文章中解释为在不同卷积核产生的神经元之间引入相互竞争。我个人觉得是做了数值规整,也就是防止数值出现太大或者太小的情况,有利于网络训练过程中的数值平稳性;
- Pooling:文章中解释为对相邻神经元进行归纳。我认为应该是消除图像中存在的空间冗余性,也就是说图像中相邻单元存在相似的语义,而pooling操作有效地消除了这种冗余,抓住了网络的主要响应,忽略了非主要的噪声干扰,并且降低了特征的维度大小,降低了网络过拟合的风险;
- Dropout:这种方法通过在训练的过程中,以一定的概率随机将神经元置零,从而降低了神经元之间的相互依赖耦合关系,实验表明可以有效地降低网络过拟合的风险。有人将此解释为保持网络的多样性,或者某种形式的Ensemble。但是,我认为还是存在较大的区别,对其合理性存在较大的疑惑;
- Weight decay:weight decay在没有SGD作用的情况下,其作用就是网络权重随着训练次数的增加按照指数衰减的方式逐步减少。如果被衰减的参数对网络重要,那么SGD会产生一个梯度使得衰减的网络权重重新得到补偿;如果网络的某个权重参数并不重要,那么SGD对这个权重的作用较小,而weight decay的作用相对较大,那么这个权重就会随着训练迭代次数的增加而不断减小。总之,weight decay的作用就是让网络中的权值的绝对值大小尽可能的小,消除那些无用的参数,发挥了正则化的作用。文章中实验表明,weight decay也可以降低训练误差(而正则化是降低验证误差);
VGG
VGG是AlexNet的增强版。相比较于AlexNet,一方面,VGG将AlexNet中的大小为11×11和5×5的卷积核分解成了一系列大小为3×3的小卷积核,并且增加了网络的深度,例如5×5的卷积核在感受野不变的情况下,可以分解为2个3×3的卷积核。另外一方面,将pooling层都改成了2×2大小的。这样做的好处有以下2个好处:
-
可以在分解后的卷积层中加入更多的非线性激活函数,使得网络的非线性决策能力得到增加;
-
可以在相同感受野的情况下,减少网络的参数,降低了网络的过拟合风险和训练数据来给你要求。例如一个大小为5×5的卷积核分解为2个3×3的卷积核之后,其参数量由25转变成了18个,越大的卷积核分解后其较少的参数越多。
VGG还引入了1×1的卷积核,结合非线性激活函数,可以在不改变网络感受野的情况下,增加网络的非线性,使得网络可以获得非线性更强的决策边界。另外,VGG也意识到了网络的深度对网络的性能表现的重要性。由于VGG简洁的结构特征和高效的特征表达能力,其网络结构被作为基础模型用于其他视觉任务的CNN网络中,如RCNN和FCN,其网络结构如下所示:
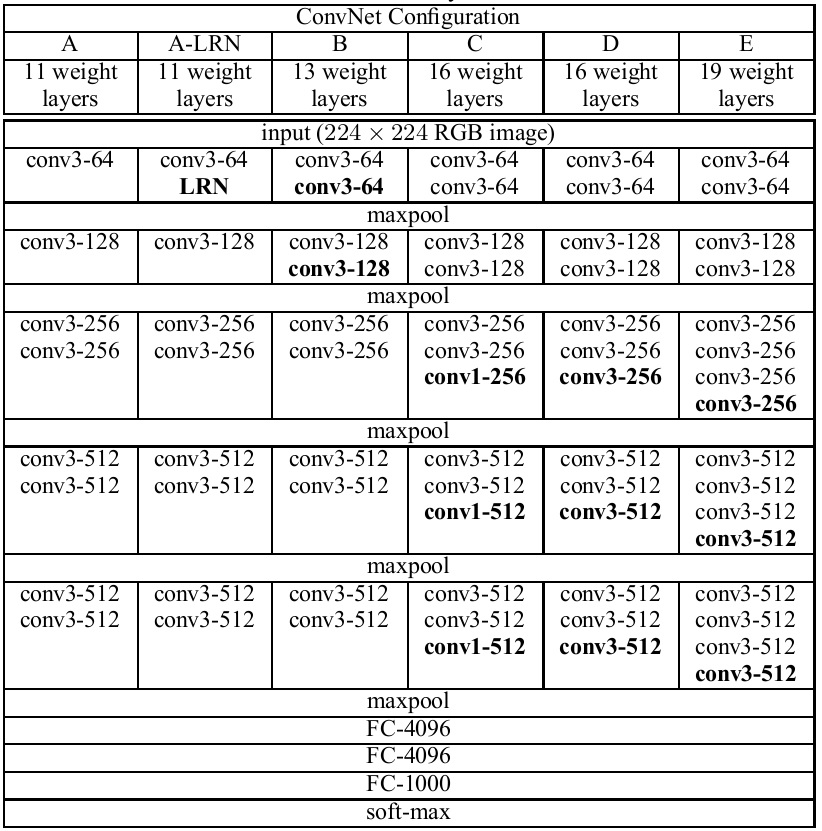
从网络结构中可以看到,除了最后一层卷积层,每次进行max pooling之后,feature map的通道数(或者说kernel的数量)都增加了一倍。我觉得应该是尽可能保留多的语义信息,同时把不同的语义逐步分开(细分到不同的通道中),这样学习到的特征具有更好的可区分性。
GoogLeNet
GoogLeNet相比较于之前的网络,引入了Inception模块,增加了多尺度特征学习能力,同时考虑到了网络深度宽度对网络性能表现的影响。其中,网络的深度对应了感受野的大小,网络的宽度对应了尺度,Inception结构如下图所示。
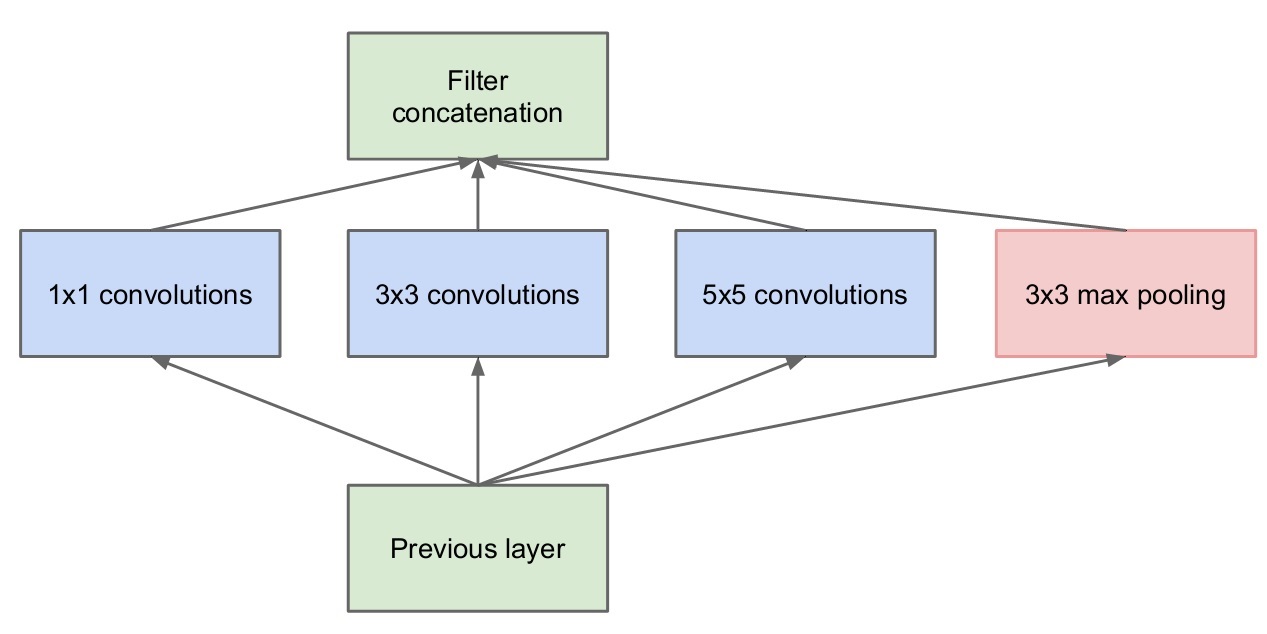
上述Inception模块引入了各种大小的卷积核,其中有比较大的5×5卷积核,会使得网络的参数量急剧增加,随着feature map通道数的增加,其参数量将更加庞大,从而加重计算负担并增加网络的收敛困难。因此,为了降低网络的参数量,GoogLeNet引入了1×1的卷积核用于降低输入到大卷积核中feature map的通道数,如下图所示。
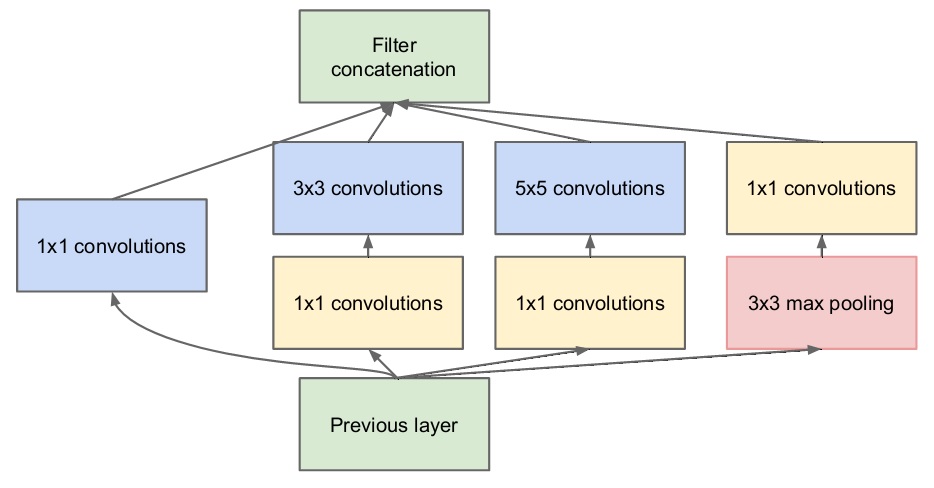
例如Previous layer输出的feature map大小为28×28×96,经过“5×5 convolutions”前面的大小为1×1×16的卷积核,那么实际输入到“5×5 convolutions”中的feature map的大小为28×28×16,因此“5×5 convolutions”的参数量从5×5×96变成了5×5×16。简而言之,1×1的卷积核发挥了降低通道方向维度的作用。上述Inception模块中输入的Previous layer和Filter concatenation的feature map的宽高大小是一样的。
GoogLeNet的网络结构如下所示
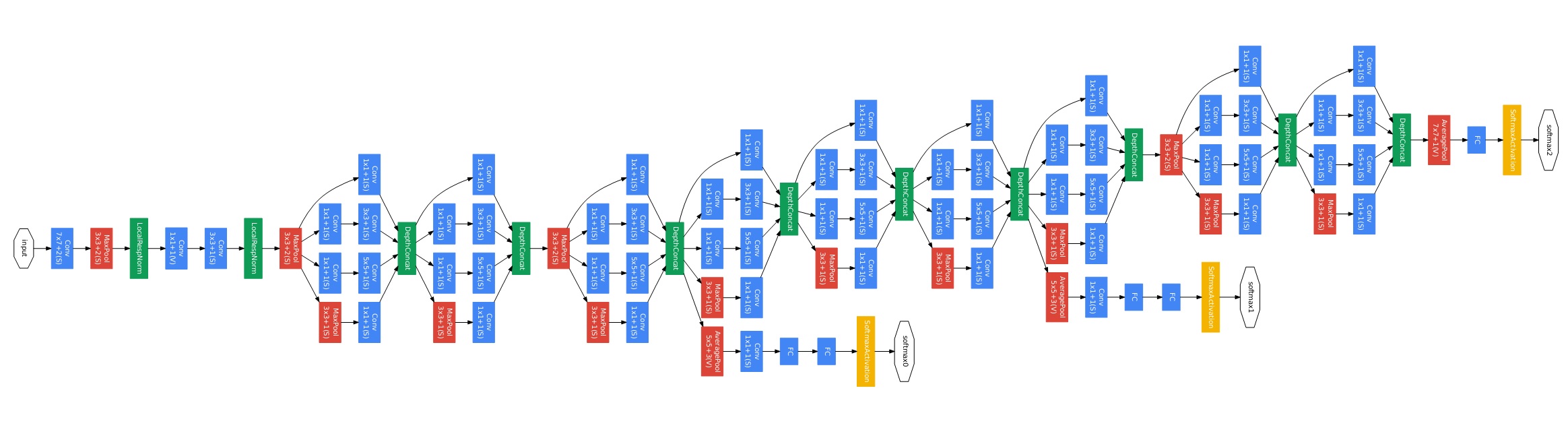
从网络结构中可以看到:
-
网络包括了9个Inception模块,每个Inception模块有1×1 、3×3 和5×5 大小的感受野。通过串联的Inception模块,形成了各种尺度大小的排列组合,可以产生更多尺度的感受野,对输入图像中不同尺度大小的物体有更好的适应能力;
-
相对于AlexNet的5层卷积网络,GoogLeNet的深度增加到了22层。如果梯度只从最后一层损失层往前传播的话,那么前面的卷积层的梯度就会很小,无法进行有效的学习,这种现象被称为梯度消失问题。为了解决这一问题,GoogLeNet在网络的中间层加入了一些辅助的分类器softmax0和softmax1。
ResNet
借鉴VGG和GoogLeNet的经验,ResNet将网络深度对网络性能提升的潜力发挥到了极致。论文中发现了34层的普通卷积网络的训练误差比18层的网络更高,提出了简单增加网络深度会使得网络的性能退化的问题。同时观察到其他领域中,如VLAD和PDE中,Residual Representation可以有效地提高算法的效率。受到Highway network的启发,提出了Residual Network,有效地提高了深层网络的收敛速度和收敛精度。
与普通网络的做法不同,Residual Network不直接拟合目标函数,而是去拟合目标函数的残差。Residual Network中的residual block如下图所示。
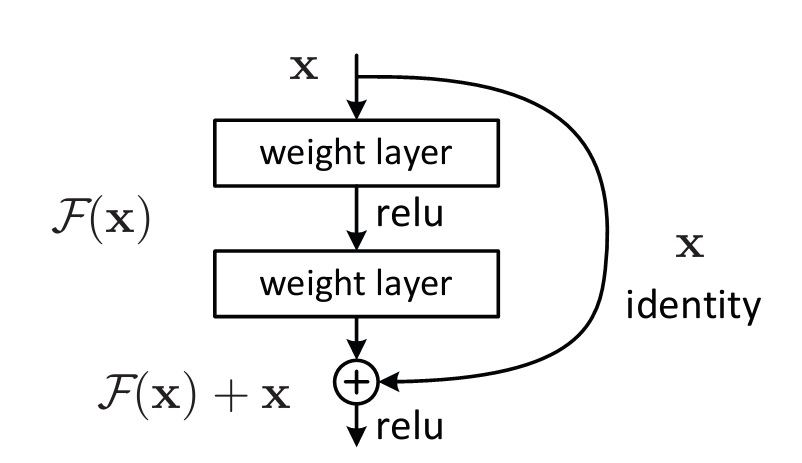
具体来说,假设网络中的某一部分,其输入为x,需要拟合的函数了H(x),那么就将x作为拟合目标函数的初始值,而网络实际需要拟合的函数为目标函数的残差F(x)=H(x)-x。相对于直接拟合目标函数的网络来说,residual network在初始值选择上有很大的优势,也就是说初始值x在某种程度上是比随机初始化更加接近目标函数,从而可以简化、明确网络学习的目标,学习目标就是学习输入和输出之间的差异。
上面的网络结构需要解决一个问题,那就是输入x要和F(x)进行求和,那么x和F(x)必须具有相同的维度。最简单直接的方法就是直接保持F(x)和x的维度相同,如下图左边所示。
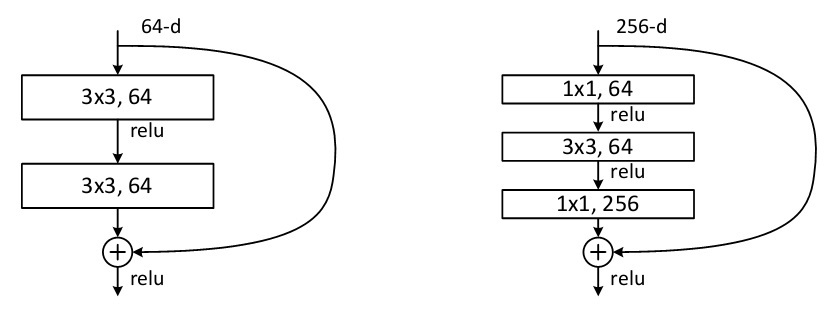
如果按照上图左边的方式进行设计,如果输入的feature map的通道数较多,那么就会引起3×3卷积的参数量很大,尤其在整个网络结构比较深的时候,这种情况是无法接受的。因此,ResNet借鉴了GoogLeNet中降低输入feature map维度的方法,引入了大小为1×1的卷积核,如上图的右边所示。在输入通道数为256维的feature map时,见用一个1×1的卷积核将feature map的通道数降为64,然后再输入到参数量相对较大的3×3卷积核中,输出的feature map的通道数也相对较小为64。在输出残差结果F(x)时,又通过1×1的卷积核,将feature map的通道数增加到256,从而和输入x保持相同的维度。
对ResNet收敛速度快的形式化理解如下:
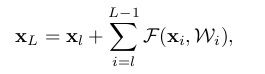
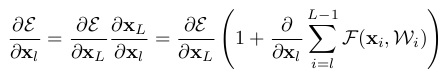
其中下$x_l$表示第$l$个residual block的输入,$x_L$表示第$L$个residual block的输出,$F(x_i,W_i)$表示对应层的residual block,$\epsilon$表示网络的loss。公式1表示:第$l$个到第$L$个的residual block组成的网络的输出函数;公式2表示从第$L$个residual block转播到第$l$个residual block的梯度,可以看到不同层之间的梯度是求和的关系而非乘积的关系,并且第$L$个residual block产生的梯度可以直接转播到第$l$个residual block,因此,网络的梯度不会随着深度增加而不断衰减,保障了网络训练的收敛速度。
《Residual Networks are Exponential Ensembles of Relatively Shallow Networks》中提出了一种观点来解释ResNet高效性。文章认为ResNet的成功不只是在于网络的深度,同时也是因为隐式地ensemble了网络个数随着网络深度指数级增长的网络,具有丰富的多样性。ResNet的展开形式,如下图所示。
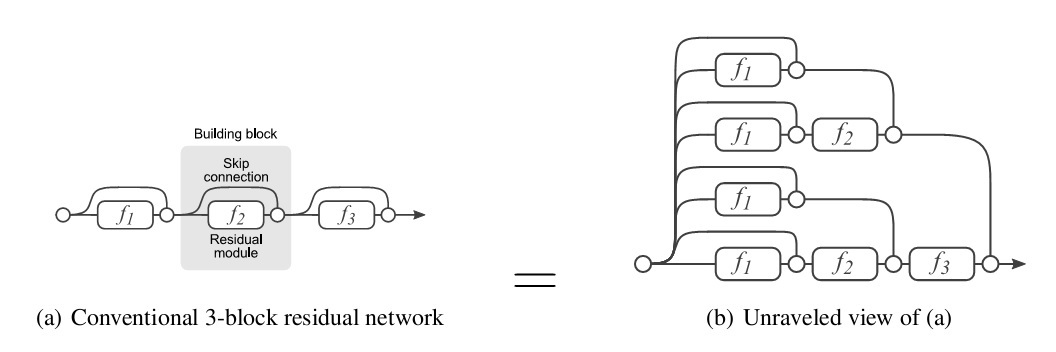
综上所述,ResNet通过增加了parameter-free的skip connect的结构,使得网络的训练效率和网络精度得到了突破性的进展,虽然后续有很多相应的改进版本,但是由于ResNet高度的简洁性而被后续的研究和应用广泛采纳,是一种十分成功的网络架构。